# ChatLocalAI
ChatLocalAI 노드는 로컬 서버에 배포된 LLM 모델을 직접 호출하는 Chat Model 노드입니다. OpenLLM, GPT4All, LLaMA 등 다양한 오픈소스 모델을 내부 네트워크에서 실행하고자 할 때 유용하며, 비용 부담 없이 독립적 환경에서 자유롭게 실험이 가능합니다.
***
#### 주요 기능
* 로컬 환경(Localhost)에서 구동 중인 LLM 모델 호출
* Base Path 및 모델 파일명을 직접 지정하여 유연한 설정 가능
* Temperature, Top-P 등 응답 제어 파라미터 지원
* Streaming 응답 처리 가능
* 외부 API 비용 없이 독립형 LLM 환경 운영 가능
WindyFlo ChatLocalAI
WindyFlo ChatLocalAI Parameters
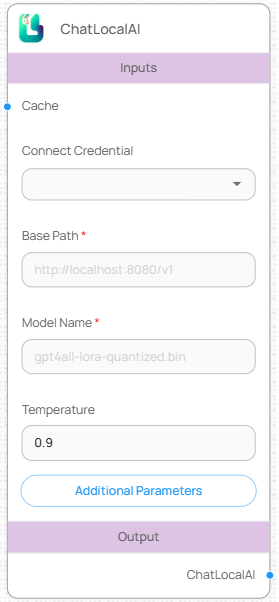
#### 입력값 (Inputs)
| 항목 | 설명 | 필수 여부 |
| ------------------ | ------------------------------------------------------- | ----- |
| Connect Credential | API Key 또는 로컬 서버 인증 정보 (Credential에 등록된 값) | 선택 |
| Base Path | LLM API가 실행 중인 로컬 서버 주소 (예: ) | 필수 |
| Model Name | 실행 중인 로컬 모델 파일명 (예: gpt4all-lora-quantized.bin) | 필수 |
| Temperature | 응답의 창의성 조절 값 (0.0 \~ 1.0, 기본값: 0.9) | 선택 |
***
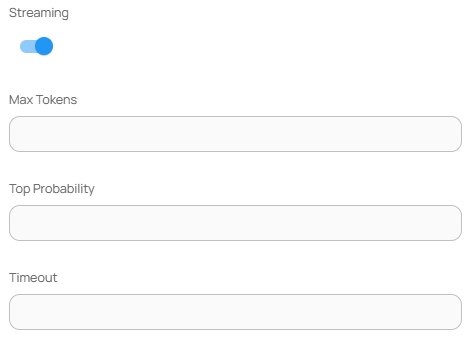
#### 파라미터 (Parameters)
| 항목 | 설명 |
| --------------- | -------------------------- |
| Streaming | 실시간 응답 스트리밍 여부 (기본값: true) |
| Max Tokens | 응답 최대 토큰 수 제한 |
| Top Probability | Top-P 확률 기반 샘플링 값 |
| Timeout | API 응답 제한 시간(ms) |
***
#### 출력값 (Outputs)
| 출력 항목 | 설명 |
| ----------- | ---------------------------- |
| ChatLocalAI | 로컬 서버 LLM의 응답 텍스트 또는 스트리밍 객체 |
***
#### 활용 예시
* **보안 환경**에서 인터넷 연결 없이 사내 문서 기반 응답 시스템 구축 (예: 내부 상담 챗봇)
* **LLM 실험용 로컬 서버**를 구축하여 모델 성능 비교 및 Prompt 최적화 테스트
* 비용 없이 운영 가능한 **개인 프로젝트** 또는 사내 MVP 챗봇 개발
* GPU 또는 CPU 환경에서 로컬 LLM 실행 후 WindyFlo를 통해 워크플로우에 연동
***
#### 사용 팁
* Base Path는 실제 API가 열려 있는 포트 및 경로와 정확히 일치해야 함 (예: `/v1/chat/completions`)
* `Model Name`은 gpt4all, llama.cpp 등에서 실제 로딩된 모델 파일명을 정확히 입력해야 함
* Top Probability 값을 0.9 이하로 설정하면 응답의 집중도를 높일 수 있음
* Streaming을 활용하면 응답 속도 체감이 향상되며, 대화형 인터페이스에 적합함
***
#### 주의사항
* 해당 노드는 로컬 서버가 이미 실행 중이어야 하며, API 스펙(gpt4all, llama.cpp 등)을 따라야 합니다
* 모델 실행 중 리소스 부족(GPU, 메모리 등)으로 인한 시간 초과나 응답 실패가 발생할 수 있음
* 로컬 환경에서는 인증 설정이 필수가 아니지만, 공유 환경에서는 Credential 설정을 권장함
* Base Path 설정 오류 또는 방화벽 설정으로 인해 연결 실패가 발생할 수 있음