# ChatOllama
ChatOllama 노드는 Ollama 로컬 서버에서 실행 중인 LLM 모델을 호출하는 Chat Model 노드입니다. llama2, mistral, codellama 등 다양한 모델을 빠르게 배포하고 세밀하게 제어할 수 있어, **개발자 중심의 실험 및 사내 배포 환경에 최적화**되어 있습니다.
***
#### 주요 기능
* 로컬에서 실행 중인 Ollama 모델(llama2, mistral 등)과 직접 통신
* Top-P, Top-K, Mirostat 등 고급 생성 파라미터 지원
* JSON Mode, Tail Free Sampling 등 특수 옵션 제공
* Streaming 응답 및 이미지 업로드 지원 가능
* GPU/스레드 수, 반복 제어 등 성능 및 응답 품질 조정 가능
WindyFlo ChatOllama
WindyFlo ChatOllama Parameters
WindyFlo ChatOllama Parameters
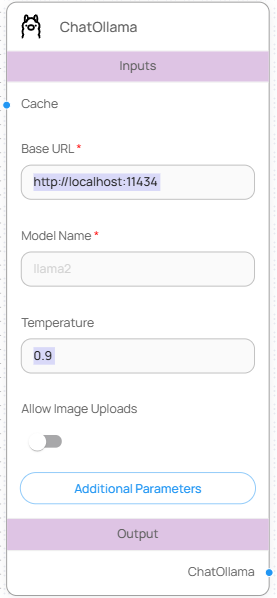
#### 입력값 (Inputs)
| 항목 | 설명 | 필수 여부 |
| ------------------- | -------------------------------------------- | ----- |
| Base URL | Ollama 서버 주소 (기본값: ) | 필수 |
| Model Name | 실행 중인 모델 이름 (예: llama2, mistral 등) | 필수 |
| Temperature | 창의성 조절 값 (0.0 \~ 1.0, 기본값: 0.9) | 선택 |
| Allow Image Uploads | 이미지 입력 활성화 여부 | 선택 |
***
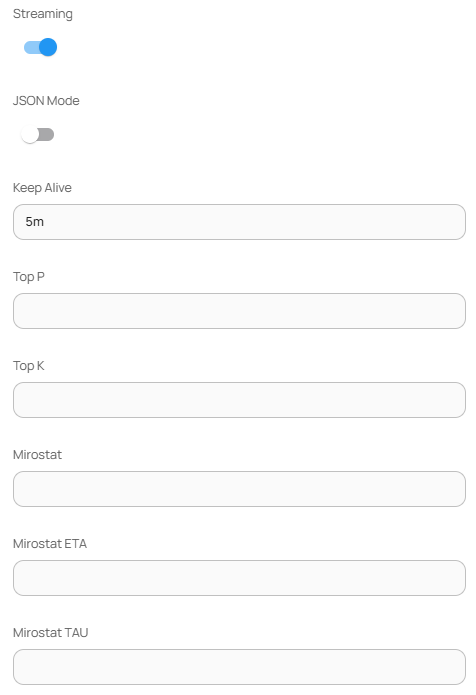
#### 파라미터 (Parameters)
| 항목 | 설명 |
| ------------------- | -------------------------- |
| Streaming | 스트리밍 응답 여부 (기본값: true) |
| JSON Mode | 응답을 JSON 형태로 제한할지 여부 |
| Keep Alive | 세션 유지를 위한 연결 지속 시간 (예: 5m) |
| Top P | 확률 기반 샘플링 값 |
| Top K | 후보 토큰 개수 제한 |
| Mirostat | 동적 확률 제어 알고리즘 (1 또는 2) |
| Mirostat ETA | Mirostat의 적응률 (예: 0.1) |
| Mirostat TAU | Mirostat의 목표 엔트로피 |
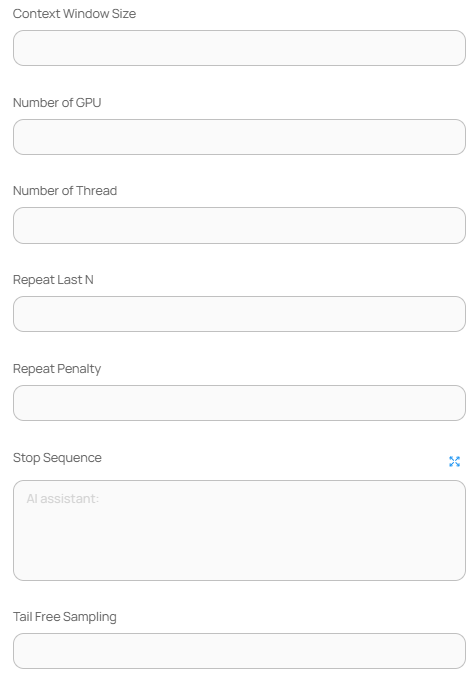
| Context Window Size | 문맥 최대 길이 |
| Number of GPU | GPU 장치 수 (0은 CPU) |
| Number of Thread | 처리 스레드 수 |
| Repeat Last N | 반복 억제를 적용할 토큰 수 |
| Repeat Penalty | 반복 억제 강도 |
| Stop Sequence | 응답 종료 조건 문자열 |
| Tail Free Sampling | 희소 샘플링 제어 계수 (0.0 \~ 1.0) |
***
#### 출력값 (Outputs)
| 출력 항목 | 설명 |
| ---------- | ----------------------- |
| ChatOllama | 로컬 모델로부터의 응답 또는 스트리밍 객체 |
***
#### 활용 예시
* llama2, mistral, codellama 등 오픈소스 모델을 **개발 테스트용으로 로컬에서 호출**
* 사내 전용 AI 시스템 구축 시 GPU 환경에 맞춘 **로컬 추론 엔진 구성**
* **코딩 지원, 요약, 번역** 등 다양한 기능을 사내망 내에서 처리
* Mirostat, Tail Free 등 고급 파라미터 실험을 통한 응답 제어 최적화
***
#### 사용 팁
* **Streaming**은 대부분의 경우 UX 개선에 효과적이며, 응답 지연을 줄이는 데 유용
* **Mirostat = 2** 설정 시 응답 일관성과 다양성의 균형을 자동 조정할 수 있음
* JSON Mode는 코드 생성 또는 파서 적용이 필요한 환경에서 유용함
* **Repeat Penalty + Repeat Last N** 조합으로 중복 표현 억제 가능
***
#### 주의사항
* Ollama 서버가 로컬에서 실행 중이어야 하며, Base URL 경로와 포트가 정확해야 함
* Model Name은 Ollama에 등록된 이름과 일치해야 하며 대소문자 주의
* GPU 또는 스레드 설정이 과도할 경우 리소스 부족 또는 응답 지연 발생 가능
* Stop Sequence를 명확히 설정하지 않으면 응답이 끝나지 않고 지속될 수 있음