# Apify Website Content Crawler
Apify 플랫폼을 활용해 웹사이트의 콘텐츠를 크롤링하고 문서로 변환하는 로더 노드입니다. 지정한 URL에서 페이지 내용을 수집하며, 크롤링 범위, 깊이, 방식 등을 유연하게 설정할 수 있어 동적 웹사이트에도 대응 가능합니다.
***
#### 주요 기능
* 지정한 Start URL 기준으로 웹 콘텐츠를 자동 수집
* Chrome, Firefox, Cheerio 등 다양한 크롤러 타입 지원
* 최대 깊이(depth)와 페이지 수 제한으로 크롤링 범위 조절
* Apify API를 통해 정교한 크롤링 제어
* 문서 변환 전 Text Splitter와 연결하여 구조화 가능
WindyFlo Apify Website Content Crawler
WindyFlo Apify Website Content Crawler Parameters
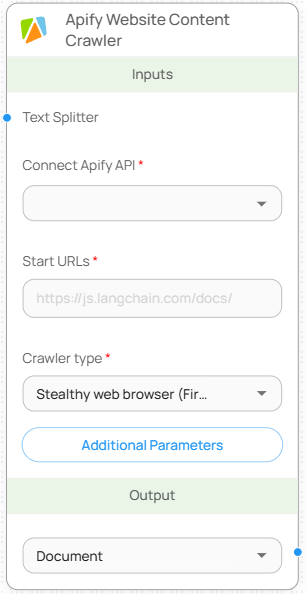
#### 입력값 (Inputs)
| 항목 | 설명 | 필수 여부 |
| ----------------- | ---------------------------------- | ----- |
| Text Splitter | 크롤링 결과 텍스트 분할 용도 | 선택 |
| Connect Apify API | Apify API Key를 Credential에 등록 후 선택 | 필수 |
| Start URLs | 크롤링 시작 대상 URL (하나 또는 복수 입력 가능) | 필수 |
| Crawler type | 사용할 크롤러 방식 선택 (Browser, HTTP 등) | 필수 |
***
#### 파라미터 (Parameters)
| 항목 | 설명 |
| ------------------- | ------------------------------ |
| Max crawling depth | 크롤링 깊이 (0=해당 페이지만, 1=링크 1단계 등) |
| Max crawl pages | 최대 크롤 페이지 수 제한 (예: 3) |
| Additional input | 크롤링 실행 시 전달할 추가 입력 값 |
| Additional Metadata | 생성된 문서에 포함할 추가 메타데이터 |
| Omit Metadata Keys | 문서에서 제외할 메타데이터 키 (쉼표로 구분) |
\*Crawler type 옵션 목록:
* Headless web browser (Chrome+Playwright)
* Stealthy web browser (Firefox+Playwright)
* Raw HTTP client (Cheerio)
* Raw HTTP client with JS execution (JSDOM)
***
#### 출력값 (Outputs)
| 출력 항목 | 설명 |
| -------- | ---------------------------------- |
| Document | 수집된 웹 콘텐츠를 기반으로 생성된 Document 객체 배열 |
| Text | 문서 내용을 하나의 문자열로 병합한 텍스트 (선택 출력 형식) |
***
#### 활용 예시
* SaaS 공식 사이트에서 자주 묻는 질문(FAQ)이나 가이드 문서를 자동 수집해 AI 응답 학습에 활용
* 동적 렌더링되는 기술 문서 페이지를 Stealthy 브라우저로 정확히 크롤링
* 특정 URL만 지정하여 콘텐츠 업데이트 여부를 추적하고 요약 제공
* 기술 블로그/제품 매뉴얼을 자동 문서화
* 경쟁사 웹사이트 콘텐츠를 수집하여 분석
* 검색엔진에 노출되지 않는 내부 링크 콘텐츠 수집 가능
***
#### 사용 팁
* `Crawler type`에서 동적 페이지인 경우 브라우저 기반 크롤러(예: Stealthy web browser)를 선택
* `Max crawling depth`를 늘릴수록 링크를 따라가는 범위가 커지므로 성능 고려
* `Max crawl pages` 설정을 통해 무한 크롤링 방지
* Start URL은 복수 입력 가능 (쉼표 또는 배열 형태)
***
#### 주의사항
* Apify API Key는 사전 발급 후 Credential에 등록 필요
* 너무 많은 링크를 포함한 사이트는 처리 시간이 길어질 수 있음
* JSDOM 타입은 실험적 기능으로 예외 발생 가능성 존재
* 사이트 robots.txt 정책을 준수해야 함
.png?alt=media)