# Cheerio Web Scraper
지정한 URL의 정적 HTML 콘텐츠를 Cheerio 기반으로 크롤링하여 문서(Document) 형식으로 변환하는 로더 노드입니다. 빠른 속도로 단일 페이지 또는 다수의 내부 링크를 크롤링할 수 있으며, CSS 셀렉터 기반 추출도 지원합니다.
***
#### 주요 기능
* Cheerio를 활용한 경량 HTML 스크래핑 기능 제공
* URL 기준 상대 링크 추출 기능(Web Crawl, XML Sitemap 방식)
* CSS Selector로 콘텐츠 영역 지정 가능
* Text Splitter 연결을 통해 장문 콘텐츠 분할 처리 가능
* 출력 형태 선택 가능: Document 또는 단일 텍스트
WindyFlo Cheerio Web Scraper
WindyFlo Cheerio Web Scraper Parameters
#### 입력값 (Inputs)
| 항목 | 설명 | 필수 여부 |
| ------------- | ---------------- | ----- |
| Text Splitter | 크롤링 결과 텍스트 분할 용도 | 선택 |
| URL | 크롤링 대상 URL | 필수 |
***
#### 파라미터 (Parameters)
| 항목 | 설명 |
| ------------------------- | ------------------------------------------------------ |
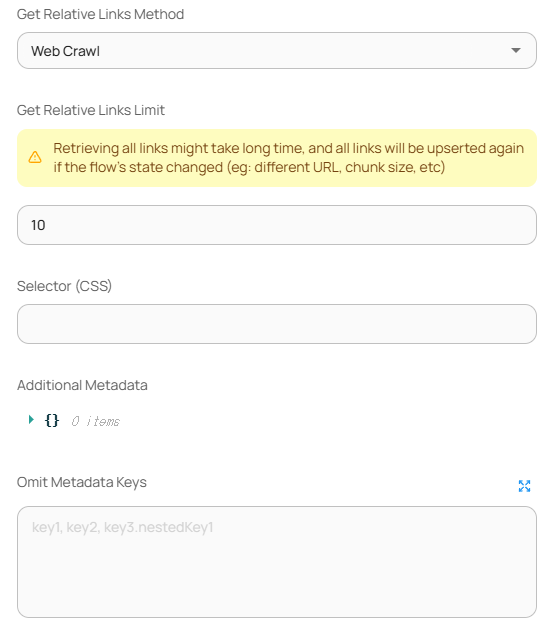
| Get Relative Links Method | 내부 링크 수집 방식 선택 (Web Crawl 또는 XML Sitemap) |
| Get Relative Links Limit | 수집할 상대 링크 최대 수 (예: 10) |
| Selector (CSS) | 추출할 콘텐츠 영역의 CSS 셀렉터 지정 (선택 시 해당 영역만 크롤링) |
| Additional Metadata | 문서에 포함할 사용자 정의 메타데이터 |
| Omit Metadata Keys | 제외할 metadata 키 (쉼표 구분, 예: `source.href, header.title`) |
***
#### 출력값 (Outputs)
| 출력 항목 | 설명 |
| -------- | ----------------------------------- |
| Document | pageContent와 metadata를 포함한 문서 객체 배열 |
| Text | 모든 문서 내용을 하나로 연결한 텍스트 (선택 출력 형식) |
***
#### 활용 예시
* 단일 웹페이지 또는 웹사이트의 서브 페이지들에서 콘텐츠 수집 및 분석
* 기술 블로그나 제품 소개 페이지의 주요 영역만 CSS Selector로 추출
* 기업 내부 위키 또는 매뉴얼 페이지를 수집해 LLM 학습에 활용
* 상대 링크 자동 수집을 통한 정적 문서 전체 크롤링 자동화
* 예: `/docs`, `/faq` 등 구조화된 콘텐츠 페이지 반복 수집
* XML Sitemap 제공 사이트의 모든 문서 자동 로딩
* 다양한 HTML 구조 대응 시 Selector 사용으로 정밀 제어
***
#### 사용 팁
* `Selector (CSS)`를 활용하면 광고나 불필요한 콘텐츠를 제거하고 핵심 내용만 추출 가능
* `Get Relative Links Method`를 `Web Crawl`로 설정 시 반복 페이지 수집 가능
* 상대 링크 수집 시 `Get Relative Links Limit`을 적절히 설정하여 과부하 방지
* Text Splitter를 연결해 긴 콘텐츠도 구조화된 처리 가능
***
#### 주의사항
* JavaScript 기반 동적 콘텐츠는 Cheerio로 수집되지 않음 (정적 HTML 전용)
* 상대 링크 자동 수집 시 페이지 수에 따라 크롤링 시간이 길어질 수 있음
* `Web Crawl` 방식은 반복 실행 시 동일한 링크가 중복 처리될 수 있음
* Selector 입력 오류 시 콘텐츠가 추출되지 않을 수 있음
.png?alt=media)